Investigating the correlation between high precipitation events and 311 street flooding complaints in New York City#
Author: Mark Bauer
Objective: Ground-truthing 311 street flooding complaints to actual precipitation levels.#
The NYC 311 is a fantastic system to alert the City of non-emergency services such as garbage and trash removal, noise levels, dirty sidewalks, etc. Department of Environmental Protection (DEP) is tasked with responding to 311’s Street Flooding complaints. While 311 is not directly intended to measure and observe flooding events, studies show that 311 street flooding complaints might be linked to actual flooding and have the potential to reveal areas that require greater sewer maintenence and resources.
This analysis is designed to test the hypothesis that 311 Street Flooding Complaints are correlated with high precipitation events in NYC.
Links#
NYC 311: https://portal.311.nyc.gov/
About NYC 311: https://portal.311.nyc.gov/about-nyc-311/
Street Flooding Complaint Form: https://portal.311.nyc.gov/article/?kanumber=KA-02198
Data Sources#
1) 311 Steet Flooding Complaints#
311 Service Requests from 2010 to Present: https://data.cityofnewyork.us/Social-Services/311-Service-Requests-from-2010-to-Present/erm2-nwe9
2) NOAA Automated Surface/Weather Observing Systems (ASOS/AWOS)#
Precipitation Data (Hourly) from 2010 to 2020, NYC, New York (Central Park, 40.779, -73.96925)
Dataset: Automated Surface/Weather Observing Systems (ASOS/AWOS)
ASOS Mainpage: https://www.ncei.noaa.gov/products/land-based-station/automated-surface-weather-observing-systems
User guide: https://www.weather.gov/media/asos/aum-toc.pdf
Data retrieved from:
Iowa State University Environmental Mesonet: https://mesonet.agron.iastate.edu/request/asos/hourlyprecip.phtml?network=NY_ASOS
Station data: https://mesonet.agron.iastate.edu/sites/site.php?station=NYC&network=NY_ASOS
Iowa Environmental Mesonet (IEM) Computed Hourly Precipitation Totals
The IEM attempts to take the METAR reports of precipitation and then provide just the hourly precipitation totals. These totals are not for the true hour (00 to 59 after), but for the hour between the standard METAR reporting time, typically :53 or :54 after. The timestamps displayed are in Central Daylight/Standard Time and for the hour the precipitation fell. So a value for 5 PM would roughly represent the period between 4:53 and 5:53 PM.
Importing Libraries#
import numpy as np
import pandas as pd
import geopandas as gpd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
import statsmodels.api as sm
from scipy.stats import chi2_contingency
import datetime
import fiona
plt.rcParams['savefig.facecolor'] = 'white'
%matplotlib inline
Printing versions of Python modules and packages with watermark - the IPython magic extension.
%load_ext watermark
%watermark -v -p numpy,pandas,geopandas,geoplot,fiona,matplotlib.pyplot,seaborn
Python implementation: CPython
Python version : 3.8.13
IPython version : 8.4.0
numpy : 1.23.1
pandas : 1.4.3
geopandas : 0.11.1
geoplot : 0.5.1
fiona : 1.8.21
matplotlib.pyplot: unknown
seaborn : 0.11.2
Documention for installing watermark: rasbt/watermark
Retrieve Data#
Saving the data locally to my directory.
# path = 'https://mesonet.agron.iastate.edu/cgi-bin/request/hourlyprecip.py?network=NY_ASOS&station=NYC\
# &year1=2010&month1=1&day1=1&year2=2020&month2=12&day2=31&lalo=1&st=1&tz=America%2FNew_York'
# df = pd.read_csv(path)
# df.to_csv('data/hourlyprecip-nyc.csv', index=False)
ls data/
hourlyprecip-nyc.csv
Read in Data#
df = pd.read_csv('data/hourlyprecip-nyc.csv')
print('rows: {:,}\ncolumns: {}'.format(df.shape[0], df.shape[1]))
df.head()
rows: 71,597
columns: 7
| station | network | valid | precip_in | lat | lon | st | |
|---|---|---|---|---|---|---|---|
| 0 | NYC | NY_ASOS | 2010-01-01 01:00 | 0.0100 | 40.779 | -73.96925 | NY |
| 1 | NYC | NY_ASOS | 2010-01-01 22:00 | 0.0001 | 40.779 | -73.96925 | NY |
| 2 | NYC | NY_ASOS | 2010-01-01 23:00 | 0.0100 | 40.779 | -73.96925 | NY |
| 3 | NYC | NY_ASOS | 2010-01-02 00:00 | 0.0001 | 40.779 | -73.96925 | NY |
| 4 | NYC | NY_ASOS | 2010-01-02 04:00 | 0.0001 | 40.779 | -73.96925 | NY |
# My usual sanity checks of the dataframe
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 71597 entries, 0 to 71596
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 station 71597 non-null object
1 network 71597 non-null object
2 valid 71597 non-null object
3 precip_in 71597 non-null float64
4 lat 71597 non-null float64
5 lon 71597 non-null float64
6 st 71597 non-null object
dtypes: float64(3), object(4)
memory usage: 3.8+ MB
df.describe()
| precip_in | lat | lon | |
|---|---|---|---|
| count | 71597.000000 | 71597.000 | 71597.00000 |
| mean | 0.007600 | 40.779 | -73.96925 |
| std | 0.043277 | 0.000 | 0.00000 |
| min | 0.000000 | 40.779 | -73.96925 |
| 25% | 0.000000 | 40.779 | -73.96925 |
| 50% | 0.000000 | 40.779 | -73.96925 |
| 75% | 0.000000 | 40.779 | -73.96925 |
| max | 1.660000 | 40.779 | -73.96925 |
# to date_time
df['date_time'] = pd.to_datetime(df['valid'], infer_datetime_format=True)
df = df.sort_values(by='date_time').reset_index(drop=True)
# sanity check
df.head(10)
| station | network | valid | precip_in | lat | lon | st | date_time | |
|---|---|---|---|---|---|---|---|---|
| 0 | NYC | NY_ASOS | 2010-01-01 01:00 | 0.0100 | 40.779 | -73.96925 | NY | 2010-01-01 01:00:00 |
| 1 | NYC | NY_ASOS | 2010-01-01 22:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-01 22:00:00 |
| 2 | NYC | NY_ASOS | 2010-01-01 23:00 | 0.0100 | 40.779 | -73.96925 | NY | 2010-01-01 23:00:00 |
| 3 | NYC | NY_ASOS | 2010-01-02 00:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-02 00:00:00 |
| 4 | NYC | NY_ASOS | 2010-01-02 04:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-02 04:00:00 |
| 5 | NYC | NY_ASOS | 2010-01-02 05:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-02 05:00:00 |
| 6 | NYC | NY_ASOS | 2010-01-02 06:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-02 06:00:00 |
| 7 | NYC | NY_ASOS | 2010-01-03 09:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-03 09:00:00 |
| 8 | NYC | NY_ASOS | 2010-01-03 10:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-03 10:00:00 |
| 9 | NYC | NY_ASOS | 2010-01-03 14:00 | 0.0001 | 40.779 | -73.96925 | NY | 2010-01-03 14:00:00 |
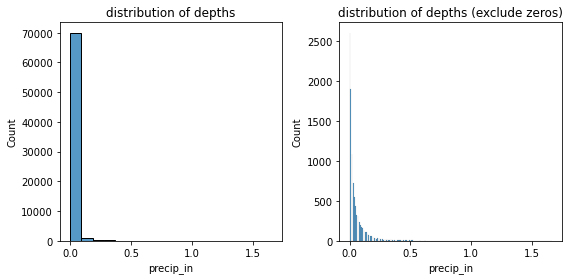
fig, axs = plt.subplots(1, 2, figsize=(8, 4))
sns.histplot(df['precip_in'], ax=axs[0])
axs[0].set_title('distribution of depths')
# removing zeros
sns.histplot(data=df.loc[df['precip_in'] > 0], x='precip_in', ax=axs[1])
axs[1].set_title('distribution of depths (exclude zeros)')
fig.tight_layout()
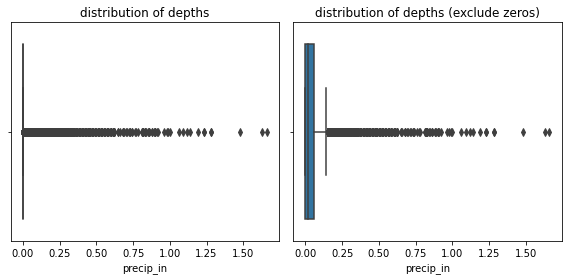
fig, axs = plt.subplots(1, 2, figsize=(8, 4))
sns.boxplot(x=df["precip_in"], ax=axs[0])
axs[0].set_title('distribution of depths')
# removing zeros
sns.boxplot(data=df.loc[df["precip_in"] > 0], x='precip_in', ax=axs[1])
axs[1].set_title('distribution of depths (exclude zeros)')
fig.tight_layout()
# highest values by date_time in NYC
fig, ax = plt.subplots(figsize=(8, 6))
(df.sort_values(by='precip_in', ascending=False)
.loc[:, ['valid', 'precip_in']]
.head()
.sort_values(by='precip_in')
.plot.barh(x='valid', y='precip_in', ax=ax, legend=False)
)
plt.title('Highest Hourly Precipitation from 2010 to 2020 (Central Park, NYC)')
plt.ylabel('Date (Hourly)')
plt.xlabel('Depth (Inches)')
plt.tight_layout()

Nice tutorial about resampling: https://www.earthdatascience.org/courses/use-data-open-source-python/use-time-series-data-in-python/date-time-types-in-pandas-python/resample-time-series-data-pandas-python/
# resample to hourly precip max and save as new dataframe
# data is already stored by hour, so we are basically just setting the index on date_time
one_hour = (
df
.set_index('date_time')[['precip_in']]
.resample('1H')
.max()
)
# sanity check
one_hour.describe()
| precip_in | |
|---|---|
| count | 71589.000000 |
| mean | 0.007601 |
| std | 0.043279 |
| min | 0.000000 |
| 25% | 0.000000 |
| 50% | 0.000000 |
| 75% | 0.000000 |
| max | 1.660000 |
# resample to 6-hour precip max and save as new dataframe
six_hour = (
df
.set_index('date_time')[['precip_in']]
.resample('6H')
.max()
)
# sanity check
six_hour.describe()
| precip_in | |
|---|---|
| count | 12423.000000 |
| mean | 0.022655 |
| std | 0.086522 |
| min | 0.000000 |
| 25% | 0.000000 |
| 50% | 0.000000 |
| 75% | 0.000100 |
| max | 1.660000 |
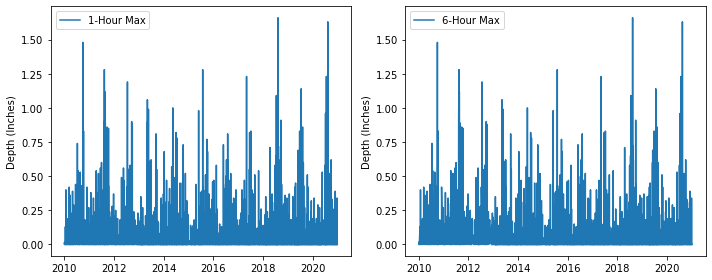
Compare 1-Hour and 6-Hour Max Precipitation Depth#
# exploratory timeseries
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
sns.lineplot(data=one_hour, legend=False, palette=('tab:blue', ), ax=axs[0])
sns.lineplot(data=six_hour, legend=False, palette=('tab:blue', ), ax=axs[1])
axs[0].legend(labels=['1-Hour Max'])
axs[1].legend(labels=['6-Hour Max'])
for ax in axs.flat:
ax.set_xlabel('')
ax.set_ylabel('Depth (Inches)')
fig.tight_layout()
Read in NYC 311 Street Flooding Complaints#
path = 'https://raw.githubusercontent.com/mebauer/nyc-311-street-flooding/\
main/data/street-flooding-complaints.csv'
complaints_df = pd.read_csv(path, low_memory=False)
print(complaints_df.shape)
complaints_df.head()
(27902, 34)
| unique_key | created_date | agency | agency_name | complaint_type | descriptor | incident_zip | incident_address | street_name | cross_street_1 | ... | location | intersection_street_1 | intersection_street_2 | closed_date | resolution_description | resolution_action_updated_date | location_type | landmark | facility_type | due_date | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 48542220 | 2020-12-31T15:41:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11420.0 | 117-17 135 STREET | 135 STREET | FOCH BLVD | ... | {'latitude': '40.67703755925495', 'longitude':... | NaN | NaN | 2021-01-01T00:20:00.000 | Please call 311 for further information. If yo... | 2021-01-01T00:20:00.000 | NaN | NaN | NaN | NaN |
| 1 | 48536430 | 2020-12-31T14:49:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11357.0 | 20-24 150 STREET | 150 STREET | 20 AVE | ... | {'latitude': '40.78072630540092', 'longitude':... | NaN | NaN | 2021-01-04T10:15:00.000 | The Department of Environment Protection inspe... | 2021-01-04T10:15:00.000 | NaN | NaN | NaN | NaN |
| 2 | 48539361 | 2020-12-31T14:03:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11228.0 | 7223 8 AVENUE | 8 AVENUE | 72 ST | ... | {'latitude': '40.62849640806448', 'longitude':... | NaN | NaN | 2021-01-02T11:25:00.000 | The Department of Environmental Protection has... | 2021-01-02T11:25:00.000 | NaN | NaN | NaN | NaN |
| 3 | 48543132 | 2020-12-31T13:48:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 10032.0 | NaN | NaN | NaN | ... | {'latitude': '40.841051689545516', 'longitude'... | RIVERSIDE DRIVE | WEST 165 STREET | 2020-12-31T14:50:00.000 | Please call 311 for further information. If yo... | 2020-12-31T14:50:00.000 | NaN | NaN | NaN | NaN |
| 4 | 48536441 | 2020-12-31T13:10:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11234.0 | 3123 FILLMORE AVENUE | FILLMORE AVENUE | E 31 ST | ... | {'latitude': '40.609203447399906', 'longitude'... | NaN | NaN | 2021-01-03T10:45:00.000 | The Department of Environmental Protection ins... | 2021-01-03T10:45:00.000 | NaN | NaN | NaN | NaN |
5 rows × 34 columns
complaints_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27902 entries, 0 to 27901
Data columns (total 34 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 unique_key 27902 non-null int64
1 created_date 27902 non-null object
2 agency 27902 non-null object
3 agency_name 27902 non-null object
4 complaint_type 27902 non-null object
5 descriptor 27902 non-null object
6 incident_zip 27045 non-null float64
7 incident_address 17865 non-null object
8 street_name 17865 non-null object
9 cross_street_1 24148 non-null object
10 cross_street_2 24137 non-null object
11 address_type 27896 non-null object
12 city 27048 non-null object
13 status 27902 non-null object
14 community_board 27900 non-null object
15 bbl 16159 non-null float64
16 borough 27900 non-null object
17 x_coordinate_state_plane 26959 non-null float64
18 y_coordinate_state_plane 26959 non-null float64
19 open_data_channel_type 27902 non-null object
20 park_facility_name 27902 non-null object
21 park_borough 27900 non-null object
22 latitude 26959 non-null float64
23 longitude 26959 non-null float64
24 location 26959 non-null object
25 intersection_street_1 10091 non-null object
26 intersection_street_2 10091 non-null object
27 closed_date 27900 non-null object
28 resolution_description 27896 non-null object
29 resolution_action_updated_date 27902 non-null object
30 location_type 0 non-null float64
31 landmark 0 non-null float64
32 facility_type 0 non-null float64
33 due_date 1 non-null object
dtypes: float64(9), int64(1), object(24)
memory usage: 7.2+ MB
# sanity check, only one 311 descriptor in this dataset - street flooding
complaints_df['descriptor'].value_counts()
Street Flooding (SJ) 27902
Name: descriptor, dtype: int64
# to date_time
complaints_df['date_time'] = pd.to_datetime(complaints_df['created_date'], infer_datetime_format=True)
complaints_df = complaints_df.sort_values(by='date_time').reset_index(drop=True)
# sanity check
complaints_df.head()
| unique_key | created_date | agency | agency_name | complaint_type | descriptor | incident_zip | incident_address | street_name | cross_street_1 | ... | intersection_street_1 | intersection_street_2 | closed_date | resolution_description | resolution_action_updated_date | location_type | landmark | facility_type | due_date | date_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 15639934 | 2010-01-02T08:26:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11229.0 | 39 DARE COURT | DARE COURT | LOIS AVE | ... | NaN | NaN | 2010-01-03T08:45:00.000 | The Department of Environmental Protection ins... | 2010-01-03T08:45:00.000 | NaN | NaN | NaN | NaN | 2010-01-02 08:26:00 |
| 1 | 15640572 | 2010-01-02T12:00:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 10302.0 | NaN | NaN | NEWARK AVE | ... | NEWARK AVENUE | RICHMOND TERRACE | 2010-01-02T15:12:00.000 | Please call 311 for further information. If yo... | 2010-01-02T15:12:00.000 | NaN | NaN | NaN | 1900-01-02T00:00:00.000 | 2010-01-02 12:00:00 |
| 2 | 15640664 | 2010-01-02T17:45:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11436.0 | 116-14 146 STREET | 146 STREET | 116 AVE | ... | NaN | NaN | 2010-01-12T11:00:00.000 | The Department of Environment Protection inspe... | 2010-01-12T11:00:00.000 | NaN | NaN | NaN | NaN | 2010-01-02 17:45:00 |
| 3 | 15655327 | 2010-01-04T16:47:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11428.0 | 94-18 218 STREET | 218 STREET | 94 AVE | ... | NaN | NaN | 2010-01-12T10:35:00.000 | The Department of Environment Protection inspe... | 2010-01-12T10:35:00.000 | NaN | NaN | NaN | NaN | 2010-01-04 16:47:00 |
| 4 | 15668560 | 2010-01-05T10:37:00.000 | DEP | Department of Environmental Protection | Sewer | Street Flooding (SJ) | 11234.0 | 2330 EAST 63 STREET | EAST 63 STREET | OHIO WALK | ... | NaN | NaN | 2010-01-08T09:00:00.000 | The Department of Environment Protection inspe... | 2010-01-08T09:00:00.000 | NaN | NaN | NaN | NaN | 2010-01-05 10:37:00 |
5 rows × 35 columns
6-Hour Max Depth vs. 6-Hour Complaint Counts#
# resample to 6-hour precip max and save as new dataframe
hour_six_max = (
df
.set_index('date_time')[['precip_in']]
.resample('6H')
.max()
)
hour_six_max['precip_in'] = hour_six_max['precip_in'].fillna(0)
hour_six_max.loc[hour_six_max['precip_in'] > 0, ['rain_flag']] = 1
hour_six_max['rain_flag'] = hour_six_max['rain_flag'].fillna(0)
hour_six_max['rain_flag'] = hour_six_max['rain_flag'].astype(int)
# sanity check
hour_six_max.head()
| precip_in | rain_flag | |
|---|---|---|
| date_time | ||
| 2010-01-01 00:00:00 | 0.0100 | 1 |
| 2010-01-01 06:00:00 | 0.0000 | 0 |
| 2010-01-01 12:00:00 | 0.0000 | 0 |
| 2010-01-01 18:00:00 | 0.0100 | 1 |
| 2010-01-02 00:00:00 | 0.0001 | 1 |
# Resample to 6-hour complaint count and save as new dataframe
complaints_hourly = (
complaints_df
.set_index('date_time')[['unique_key']]
.resample('6H')
.count()
.rename(columns={'unique_key':'count'})
)
complaints_hourly['count'] = complaints_hourly['count'].fillna(0)
complaints_hourly.loc[complaints_hourly['count'] > 0, 'complaint_flag'] = 1
complaints_hourly['complaint_flag'] = complaints_hourly['complaint_flag'].fillna(0)
complaints_hourly['complaint_flag'] = complaints_hourly['complaint_flag'].astype(int)
# sanity check
complaints_hourly.head()
| count | complaint_flag | |
|---|---|---|
| date_time | ||
| 2010-01-02 06:00:00 | 1 | 1 |
| 2010-01-02 12:00:00 | 2 | 1 |
| 2010-01-02 18:00:00 | 0 | 0 |
| 2010-01-03 00:00:00 | 0 | 0 |
| 2010-01-03 06:00:00 | 0 | 0 |
# merge both datasets on date_time
merged_df = (
hour_six_max.merge(
complaints_hourly,
left_index=True,
right_index=True,
how='left')
)
merged_df['count'] = merged_df['count'].fillna(0).astype(int)
merged_df['complaint_flag'] = merged_df['complaint_flag'].fillna(0).astype(int)
# sanity check
merged_df.head()
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| date_time | ||||
| 2010-01-01 00:00:00 | 0.0100 | 1 | 0 | 0 |
| 2010-01-01 06:00:00 | 0.0000 | 0 | 0 | 0 |
| 2010-01-01 12:00:00 | 0.0000 | 0 | 0 | 0 |
| 2010-01-01 18:00:00 | 0.0100 | 1 | 0 | 0 |
| 2010-01-02 00:00:00 | 0.0001 | 1 | 0 | 0 |
Qualitative Analysis - 311 Complaint vs. Rain Event#
Highest Events#
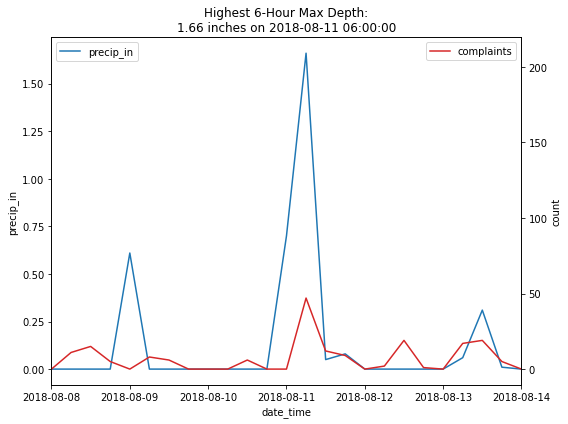
merged_df.sort_values(by='precip_in', ascending=False).head(5)
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| date_time | ||||
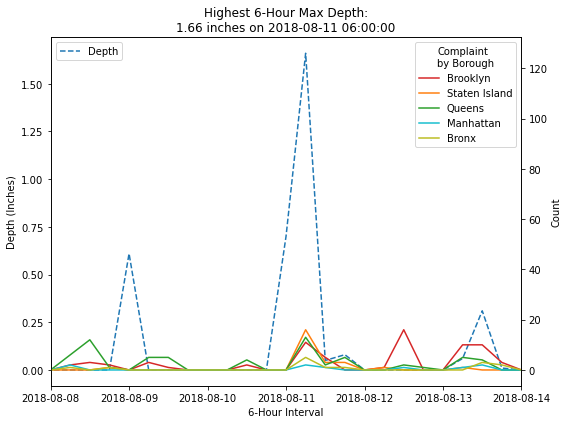
| 2018-08-11 06:00:00 | 1.66 | 1 | 47 | 1 |
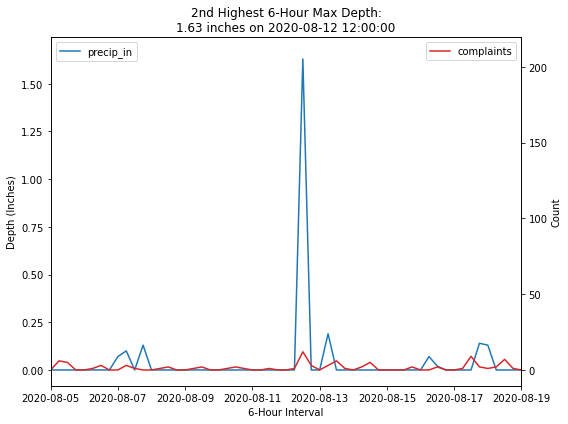
| 2020-08-12 12:00:00 | 1.63 | 1 | 12 | 1 |
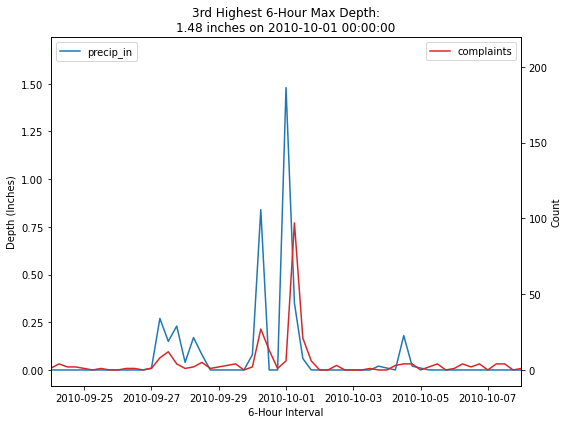
| 2010-10-01 00:00:00 | 1.48 | 1 | 6 | 1 |
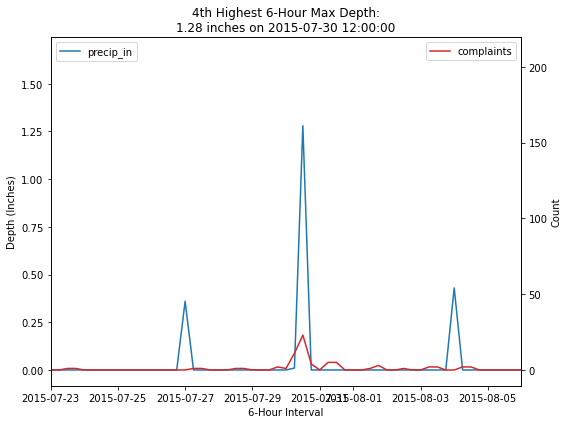
| 2015-07-30 12:00:00 | 1.28 | 1 | 23 | 1 |
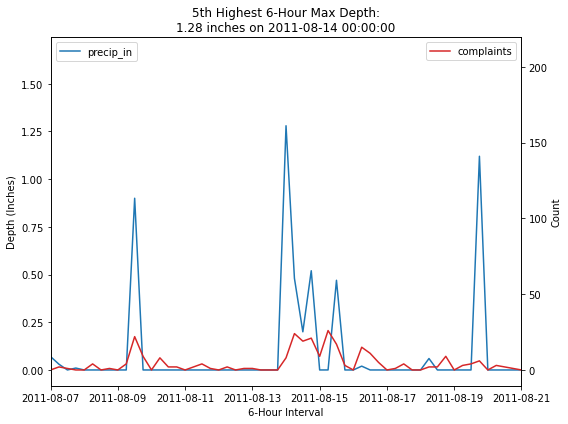
| 2011-08-14 00:00:00 | 1.28 | 1 | 8 | 1 |
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='precip_in',
color='tab:blue',
ax=ax1)
sns.lineplot(data=merged_df,
x=merged_df.index,
y='count',
label='complaints',
color='tab:red',
ax=ax2)
ax1.set_xlim([datetime.date(2018, 8, 8), datetime.date(2018, 8, 14)])
ax1.legend(loc=2)
ax2.legend(loc=1)
depth = merged_df.sort_values(by='precip_in', ascending=False).head(1)['precip_in'].values[0]
event = merged_df.sort_values(by='precip_in', ascending=False).head(1).index[0]
plt.title('Highest 6-Hour Max Depth:\n{} inches on {}'.format(depth, event))
plt.tight_layout()
# Create new dataframe by each borough
concat_df = pd.DataFrame()
boros = ['BROOKLYN', 'STATEN ISLAND', 'QUEENS', 'MANHATTAN', 'BRONX']
for boro in boros:
complaints_hourly = (
complaints_df
.loc[complaints_df['borough'] == boro]
.set_index(['date_time'])[['unique_key']]
.resample('6H')
.count()
.rename(columns={'unique_key':'count'})
)
complaints_hourly['boro'] = boro
# append each borough stats to a new dataframe
concat_df = pd.concat([complaints_hourly, concat_df])
# plot creation
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
# plot precipitation
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='Depth',
linestyle='--',
color='tab:blue',
ax=ax1)
boros = ['BROOKLYN', 'STATEN ISLAND', 'QUEENS', 'MANHATTAN', 'BRONX']
colors = ['tab:red', 'tab:orange', 'tab:green', 'tab:cyan', 'tab:olive']
# plot each borough's counts
for boro, color in zip(boros, colors):
sns.lineplot(data=concat_df.loc[concat_df['boro'] == boro],
legend=False,
palette=(color,),
ax=ax2)
ax2.set_xlim([datetime.date(2018, 8, 8), datetime.date(2018, 8, 14)])
ax2.legend(title='Complaint\nby Borough', labels=[x.title() for x in boros], loc=1)
ax1.legend(loc=2)
ax1.set_xlabel('6-Hour Interval')
ax1.set_ylabel('Depth (Inches)')
ax2.set_ylabel('Count')
depth = merged_df.sort_values(by='precip_in', ascending=False).head(1)['precip_in'].values[0]
event = merged_df.sort_values(by='precip_in', ascending=False).head(1).index[0]
plt.title('Highest 6-Hour Max Depth:\n{} inches on {}'.format(depth, event))
fig.tight_layout()
Additional High Depth Events#
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='precip_in',
color='tab:blue',
ax=ax1)
sns.lineplot(data=merged_df,
x=merged_df.index,
y='count',
label='complaints',
color='tab:red',
ax=ax2)
ax1.set_xlim([datetime.date(2020, 8, 5), datetime.date(2020, 8, 19)])
ax1.legend(loc=2)
ax2.legend(loc=1)
ax1.set_xlabel('6-Hour Interval')
ax1.set_ylabel('Depth (Inches)')
ax2.set_ylabel('Count')
depth = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[1]['precip_in']
event = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[[1]].index[0]
plt.title('2nd Highest 6-Hour Max Depth:\n{} inches on {}'.format(depth, event))
fig.tight_layout()
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='precip_in',
color='tab:blue',
ax=ax1)
sns.lineplot(data=merged_df,
x=merged_df.index,
y='count',
label='complaints',
color='tab:red',
ax=ax2)
ax1.set_xlim([datetime.date(2010, 9, 24), datetime.date(2010, 10, 8)])
ax1.legend(loc=2)
ax2.legend(loc=1)
ax1.set_xlabel('6-Hour Interval')
ax1.set_ylabel('Depth (Inches)')
ax2.set_ylabel('Count')
depth = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[2]['precip_in']
event = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[[2]].index[0]
plt.title('3rd Highest 6-Hour Max Depth:\n{} inches on {}'.format(depth, event))
fig.tight_layout()
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='precip_in',
color='tab:blue',
ax=ax1)
sns.lineplot(data=merged_df,
x=merged_df.index,
y='count',
label='complaints',
color='tab:red',
ax=ax2)
ax1.set_xlim([datetime.date(2015, 7, 23), datetime.date(2015, 8, 6)])
ax1.legend(loc=2)
ax2.legend(loc=1)
ax1.set_xlabel('6-Hour Interval')
ax1.set_ylabel('Depth (Inches)')
ax2.set_ylabel('Count')
depth = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[3]['precip_in']
event = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[[3]].index[0]
plt.title('4th Highest 6-Hour Max Depth:\n{} inches on {}'.format(depth, event))
fig.tight_layout()
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='precip_in',
color='tab:blue',
ax=ax1)
sns.lineplot(data=merged_df,
x=merged_df.index,
y='count',
label='complaints',
color='tab:red',
ax=ax2)
ax1.set_xlim([datetime.date(2011, 8, 7), datetime.date(2011, 8, 21)])
ax1.legend(loc=2)
ax2.legend(loc=1)
ax1.set_xlabel('6-Hour Interval')
ax1.set_ylabel('Depth (Inches)')
ax2.set_ylabel('Count')
depth = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[4]['precip_in']
event = merged_df.sort_values(by='precip_in', ascending=False).head(5).iloc[[4]].index[0]
plt.title('5th Highest 6-Hour Max Depth:\n{} inches on {}'.format(depth, event))
fig.tight_layout()
Highest 311 Street Flooding Count Event#
merged_df.sort_values(by='count', ascending=False).head(10)
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| date_time | ||||
| 2017-05-05 12:00:00 | 1.23 | 1 | 209 | 1 |
| 2016-02-08 06:00:00 | 0.03 | 1 | 141 | 1 |
| 2018-04-16 06:00:00 | 0.71 | 1 | 124 | 1 |
| 2013-05-08 06:00:00 | 1.06 | 1 | 123 | 1 |
| 2020-07-10 12:00:00 | 0.96 | 1 | 117 | 1 |
| 2014-12-09 06:00:00 | 0.28 | 1 | 111 | 1 |
| 2014-12-09 12:00:00 | 0.32 | 1 | 104 | 1 |
| 2014-11-17 12:00:00 | 0.52 | 1 | 103 | 1 |
| 2010-10-01 06:00:00 | 0.35 | 1 | 97 | 1 |
| 2010-12-01 12:00:00 | 0.42 | 1 | 94 | 1 |
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='precip_in',
color='tab:blue',
ax=ax1)
sns.lineplot(data=merged_df,
x=merged_df.index,
y='count',
label='complaints',
color='tab:red',
ax=ax2)
ax1.legend(loc=2)
ax2.legend(loc=1)
ax1.set_xlim([datetime.date(2017, 4, 29), datetime.date(2017, 5, 12)])
ax1.set_xlabel('6-Hour Interval')
ax1.set_ylabel('Depth (Inches)')
ax2.set_ylabel('Count')
fig.tight_layout()
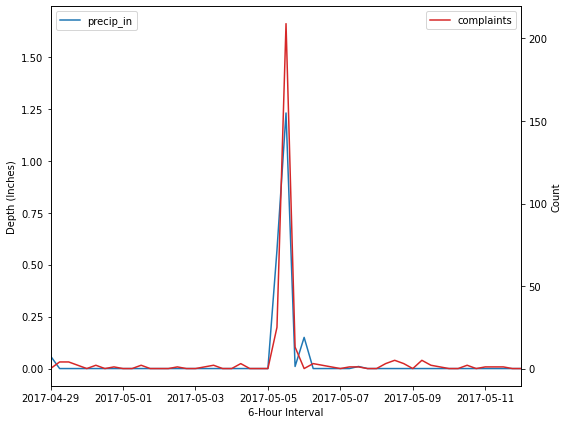
News articles:
2017-05-05: https://www.nytimes.com/2017/05/05/nyregion/flooding-new-york-roads-shutdown-rain.html
2016-02-08: https://www.cbsnews.com/newyork/news/queens-flooding-winter-storm/
2018-04-16: https://www.ny1.com/nyc/all-boroughs/news/2018/04/16/heavy-rains-causing-problems-across-nyc
2013-05-08: https://9to5mac.com/2013/05/08/leak-causes-flood-at-fifth-avenue-apple-store-employees-blame-recent-construction/
2020-07-10: https://www.nytimes.com/2020/07/10/nyregion/tropical-storm-fay-nyc.html
2014-12-09: https://www.cnn.com/2014/12/09/us/weather-record-rain/index.html
2010-10-01: https://archive.nytimes.com/cityroom.blogs.nytimes.com/2010/10/01/strong-rains-drench-morning-commute/
2010-12-01: https://dailygazette.com/2010/12/01/1201_warningfl/
Quantitative Analysis#
print('Total 6-hour intervals: {:,}\n-----'.format(len(merged_df)))
print('Normalize by row')
pd.crosstab(merged_df['complaint_flag'], merged_df['rain_flag'], normalize='index').round(2)
Total 6-hour intervals: 16,069
-----
Normalize by row
| rain_flag | 0 | 1 |
|---|---|---|
| complaint_flag | ||
| 0 | 0.86 | 0.14 |
| 1 | 0.73 | 0.27 |
crosstab = pd.crosstab(merged_df['complaint_flag'], merged_df['rain_flag'])
stat, p, dof, expected = chi2_contingency(crosstab)
# interpret p-value
alpha = 0.05
print('p value is: {}'.format(p))
if p <= alpha:
print('Dependent (reject H0)')
else:
print('Independent (H0 holds true)')
p value is: 1.1100046115880418e-101
Dependent (reject H0)
merged_df.corr(method='pearson')
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| precip_in | 1.000000 | 0.460053 | 0.466905 | 0.156828 |
| rain_flag | 0.460053 | 1.000000 | 0.267990 | 0.169044 |
| count | 0.466905 | 0.267990 | 1.000000 | 0.333616 |
| complaint_flag | 0.156828 | 0.169044 | 0.333616 | 1.000000 |
merged_df.corr(method='spearman')
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| precip_in | 1.000000 | 0.992072 | 0.247605 | 0.179753 |
| rain_flag | 0.992072 | 1.000000 | 0.230233 | 0.169044 |
| count | 0.247605 | 0.230233 | 1.000000 | 0.949662 |
| complaint_flag | 0.179753 | 0.169044 | 0.949662 | 1.000000 |
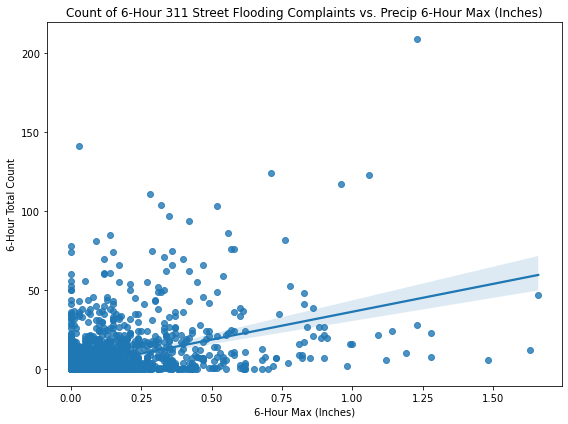
fig, ax = plt.subplots(figsize=(8, 6))
sns.regplot(data=merged_df, x="precip_in", y="count", ax=ax)
plt.title('Count of 6-Hour 311 Street Flooding Complaints vs. Precip 6-Hour Max (Inches)')
plt.xlabel('6-Hour Max (Inches)')
plt.ylabel('6-Hour Total Count')
plt.tight_layout()
scatter_hue = (
hour_six_max.merge(
concat_df,
left_index=True,
right_index=True,
how='left')
)
scatter_hue.head()
| precip_in | rain_flag | count | boro | |
|---|---|---|---|---|
| date_time | ||||
| 2010-01-01 00:00:00 | 0.0100 | 1 | NaN | NaN |
| 2010-01-01 06:00:00 | 0.0000 | 0 | NaN | NaN |
| 2010-01-01 12:00:00 | 0.0000 | 0 | NaN | NaN |
| 2010-01-01 18:00:00 | 0.0100 | 1 | NaN | NaN |
| 2010-01-02 00:00:00 | 0.0001 | 1 | NaN | NaN |
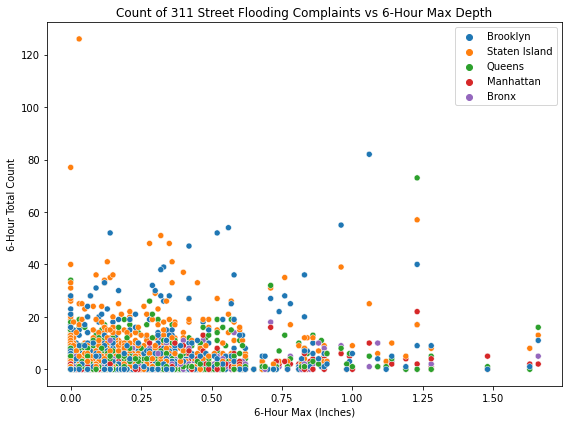
fig, ax = plt.subplots(figsize=(8, 6))
sns.scatterplot(data=scatter_hue,
x='precip_in',
y="count",
hue="boro",
ax=ax)
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles=handles, labels=[x.title() for x in boros], loc=1)
plt.title('Count of 311 Street Flooding Complaints vs 6-Hour Max Depth')
plt.xlabel('6-Hour Max (Inches)')
plt.ylabel('6-Hour Total Count')
plt.tight_layout()
Y = merged_df['count']
X = merged_df['precip_in']
X = sm.add_constant(X)
model = sm.OLS(Y,X)
results = model.fit()
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: count R-squared: 0.218
Model: OLS Adj. R-squared: 0.218
Method: Least Squares F-statistic: 4479.
Date: Wed, 15 Mar 2023 Prob (F-statistic): 0.00
Time: 23:04:33 Log-Likelihood: -49052.
No. Observations: 16069 AIC: 9.811e+04
Df Residuals: 16067 BIC: 9.812e+04
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 1.1174 0.041 26.955 0.000 1.036 1.199
precip_in 35.2803 0.527 66.926 0.000 34.247 36.314
==============================================================================
Omnibus: 25118.842 Durbin-Watson: 1.587
Prob(Omnibus): 0.000 Jarque-Bera (JB): 23851368.070
Skew: 9.798 Prob(JB): 0.00
Kurtosis: 190.722 Cond. No. 13.0
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
print('Parameters:\n{}'.format(results.params.round(4)))
print('\nR2: {}'.format(results.rsquared.round(4)))
Parameters:
const 1.1174
precip_in 35.2803
dtype: float64
R2: 0.218
Total Daily Precipitation Depth vs. Daily Complaint Counts#
# resample to daily precip sum and save as new dataframe
daily_total = (
df
.set_index('date_time')[['precip_in']]
.resample('D')
.sum()
)
daily_total['precip_in'] = daily_total['precip_in'].fillna(0)
daily_total.loc[daily_total['precip_in'] > 0, ['rain_flag']] = 1
daily_total['rain_flag'] = daily_total['rain_flag'].fillna(0)
daily_total['rain_flag'] = daily_total['rain_flag'].astype(int)
# sanity check
daily_total.head()
| precip_in | rain_flag | |
|---|---|---|
| date_time | ||
| 2010-01-01 | 0.0201 | 1 |
| 2010-01-02 | 0.0004 | 1 |
| 2010-01-03 | 0.0004 | 1 |
| 2010-01-04 | 0.0000 | 0 |
| 2010-01-05 | 0.0001 | 1 |
# resample to daily complaint count and save as new dataframe
complaints_daily = (
complaints_df
.set_index('date_time')[['unique_key']]
.resample('D')
.count()
.rename(columns={'unique_key':'count'})
)
complaints_daily['count'] = complaints_daily['count'].fillna(0).astype(int)
complaints_daily.loc[complaints_daily['count'] > 0, 'complaint_flag'] = 1
complaints_daily['complaint_flag'] = complaints_daily['complaint_flag'].fillna(0)
complaints_daily['complaint_flag'] = complaints_daily['complaint_flag'].astype(int)
complaints_daily.head()
| count | complaint_flag | |
|---|---|---|
| date_time | ||
| 2010-01-02 | 3 | 1 |
| 2010-01-03 | 0 | 0 |
| 2010-01-04 | 1 | 1 |
| 2010-01-05 | 1 | 1 |
| 2010-01-06 | 4 | 1 |
# merge dataframes on date_time
merged_df = (
daily_total.merge(
complaints_daily,
left_index=True,
right_index=True,
how='left')
)
merged_df['count'] = merged_df['count'].fillna(0)
merged_df['complaint_flag'] = merged_df['complaint_flag'].fillna(0)
merged_df['count'] = merged_df['count'].astype(int)
merged_df['complaint_flag'] = merged_df['complaint_flag'].astype(int)
merged_df.head()
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| date_time | ||||
| 2010-01-01 | 0.0201 | 1 | 0 | 0 |
| 2010-01-02 | 0.0004 | 1 | 3 | 1 |
| 2010-01-03 | 0.0004 | 1 | 0 | 0 |
| 2010-01-04 | 0.0000 | 0 | 1 | 1 |
| 2010-01-05 | 0.0001 | 1 | 1 | 1 |
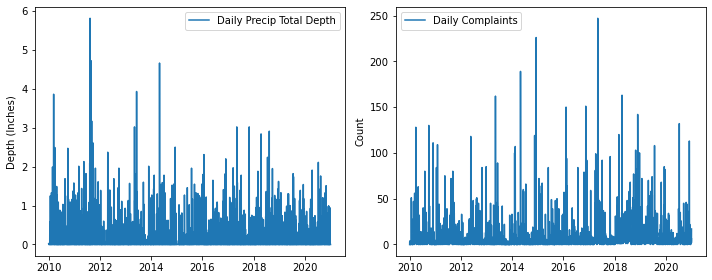
# exploratory timeseries
fig, axs = plt.subplots(1, 2, figsize=(10, 4))
sns.lineplot(data=merged_df,x=merged_df.index, y='precip_in',
legend=False, palette=('tab:blue', ), ax=axs[0])
sns.lineplot(data=merged_df, x=merged_df.index, y='count',
legend=False, palette=('tab:blue', ), ax=axs[1])
axs[0].legend(labels=['Daily Precip Total Depth'])
axs[1].legend(labels=['Daily Complaints'])
axs[0].set_ylabel('Depth (Inches)')
axs[1].set_ylabel('Count')
[ax.set_xlabel('') for ax in axs.flat]
fig.tight_layout()
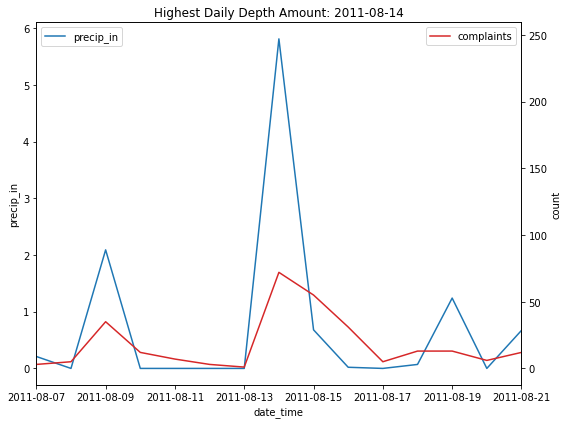
Qualitative Analysis - 311 Complaint vs. Rain Event#
Highest Event#
merged_df.sort_values(by='precip_in', ascending=False).head(1)
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| date_time | ||||
| 2011-08-14 | 5.8101 | 1 | 72 | 1 |
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='precip_in',
color='tab:blue',
ax=ax1)
sns.lineplot(data=merged_df,
x=merged_df.index,
y='count',
label='complaints',
color='tab:red',
ax=ax2)
ax1.set_xlim([datetime.date(2011, 8, 7), datetime.date(2011, 8, 21)])
ax2.set_xlim([datetime.date(2011, 8, 7), datetime.date(2011, 8, 21)])
ax1.legend(loc=2)
ax2.legend(loc=1)
event = str(merged_df.sort_values(by='precip_in', ascending=False).head(1).index[0])[:-9]
plt.title('Highest Daily Depth Amount: {}'.format(event))
plt.tight_layout()
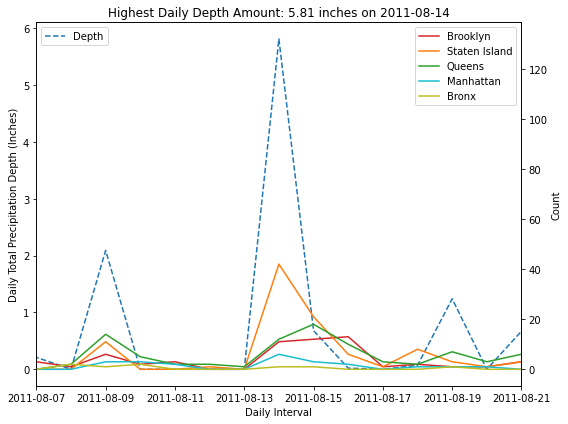
# Create new dataframe by each borough
concat_df = pd.DataFrame()
boros = ['BROOKLYN', 'STATEN ISLAND', 'QUEENS', 'MANHATTAN', 'BRONX']
for boro in boros:
complaints_daily = (
complaints_df.loc[complaints_df['borough'] == boro]
.set_index('date_time')[['unique_key']]
.resample('D')
.count()
.rename(columns={'unique_key':'count'})
)
complaints_daily['boro'] = boro
# append each borough stats to a new dataframe
concat_df = pd.concat([complaints_daily, concat_df])
# plot aesthetics
fig, ax1 = plt.subplots(figsize=(8, 6))
ax2 = ax1.twinx()
# plot precipitation
sns.lineplot(data=merged_df,
x=merged_df.index,
y='precip_in',
label='Depth',
linestyle='--',
color='tab:blue',
ax=ax1)
boros = ['BROOKLYN', 'STATEN ISLAND', 'QUEENS', 'MANHATTAN', 'BRONX']
colors = ['tab:red', 'tab:orange', 'tab:green', 'tab:cyan', 'tab:olive']
# plot each borough
for boro, color in zip(boros, colors):
sns.lineplot(data=concat_df.loc[concat_df['boro'] == boro],
legend=False,
palette=(color,),
ax=ax2)
ax2.legend(labels=[x.title() for x in boros], loc=1)
ax1.legend(loc=2)
ax1.set_xlim([datetime.date(2011, 8, 7), datetime.date(2011, 8, 21)])
ax2.set_xlim([datetime.date(2011, 8, 7), datetime.date(2011, 8, 21)])
depth = merged_df.sort_values(by='precip_in', ascending=False).head(1)['precip_in'].values[0]
event = str(merged_df.sort_values(by='precip_in', ascending=False).head(1).index[0])[:-9]
plt.title('Highest Daily Depth Amount: {:.2f} inches on {}'.format(depth, event))
ax1.set_xlabel('Daily Interval')
ax1.set_ylabel('Daily Total Precipitation Depth (Inches)')
ax2.set_ylabel('Count')
plt.tight_layout()
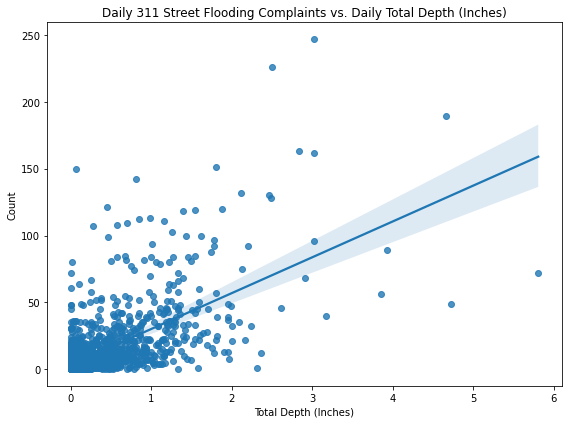
Quantitative Analysis#
print('Total daily intervals: {:,}\n-----'.format(len(merged_df)))
print('Normalize by row')
pd.crosstab(merged_df['complaint_flag'], merged_df['rain_flag'], normalize='index').round(2)
Total daily intervals: 4,018
-----
Normalize by row
| rain_flag | 0 | 1 |
|---|---|---|
| complaint_flag | ||
| 0 | 0.79 | 0.21 |
| 1 | 0.57 | 0.43 |
crosstab = pd.crosstab(merged_df['complaint_flag'], merged_df['rain_flag'])
stat, p, dof, expected = chi2_contingency(crosstab)
# interpret p-value
alpha = 0.05
print('p value is: {}'.format(p))
if p <= alpha:
print('Dependent (reject H0)')
else:
print('Independent (H0 holds true)')
p value is: 4.959973774887215e-23
Dependent (reject H0)
fig, ax = plt.subplots(figsize=(8, 6))
sns.regplot(data=merged_df, x="precip_in", y="count", ax=ax)
plt.title('Daily 311 Street Flooding Complaints vs. Daily Total Depth (Inches)')
plt.xlabel('Total Depth (Inches)')
plt.ylabel('Count')
plt.tight_layout()
merged_df.corr(method='pearson')
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| precip_in | 1.000000 | 0.439721 | 0.667650 | 0.122224 |
| rain_flag | 0.439721 | 1.000000 | 0.317658 | 0.156647 |
| count | 0.667650 | 0.317658 | 1.000000 | 0.183052 |
| complaint_flag | 0.122224 | 0.156647 | 0.183052 | 1.000000 |
merged_df.corr(method='spearman')
| precip_in | rain_flag | count | complaint_flag | |
|---|---|---|---|---|
| precip_in | 1.000000 | 0.957173 | 0.455491 | 0.172818 |
| rain_flag | 0.957173 | 1.000000 | 0.382689 | 0.156647 |
| count | 0.455491 | 0.382689 | 1.000000 | 0.596149 |
| complaint_flag | 0.172818 | 0.156647 | 0.596149 | 1.000000 |
Y = merged_df['count']
X = merged_df['precip_in']
X = sm.add_constant(X)
model = sm.OLS(Y,X)
results = model.fit()
print(results.summary())
OLS Regression Results
==============================================================================
Dep. Variable: count R-squared: 0.446
Model: OLS Adj. R-squared: 0.446
Method: Least Squares F-statistic: 3230.
Date: Wed, 15 Mar 2023 Prob (F-statistic): 0.00
Time: 23:04:36 Log-Likelihood: -15396.
No. Observations: 4018 AIC: 3.080e+04
Df Residuals: 4016 BIC: 3.081e+04
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 3.3164 0.187 17.699 0.000 2.949 3.684
precip_in 26.7883 0.471 56.832 0.000 25.864 27.712
==============================================================================
Omnibus: 3997.659 Durbin-Watson: 1.634
Prob(Omnibus): 0.000 Jarque-Bera (JB): 431827.698
Skew: 4.582 Prob(JB): 0.00
Kurtosis: 52.954 Cond. No. 2.73
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
print('Parameters:\n{}'.format(results.params.round(4)))
print('\nR2: {}'.format(results.rsquared.round(4)))
Parameters:
const 3.3164
precip_in 26.7883
dtype: float64
R2: 0.4458